
[Spring] Spring Boot + ELK 스택을 이용한 실시간 인기 검색어 Top 10 구현하기
0. Overview 2023.12.15 ~ 2024.01.12 동안 "인터파크 티켓"을 타겟으로 하여 클론코딩을 진행하게 되었는데, "공연" 도메인을 맡게 되었다. 함께 도메인을 담당하게 된 팀원과 어떤 기술을 적용해보면 좋
zero-zae.tistory.com
"인터파크 티켓" 클론코딩 프로젝트에는 Elasticsearch로 Spring Boot와 연동하여 키워드 검색 + 실시간 인기 검색어 순위 기능을 구현하였다. 한글 형태소 분석기인 nori 플러그인만 사용하고 있었으며, 검색이 잘 되나 싶었지만 정확한 의미있는 단어 단위로 검색하지 않으면 검색이 제대로 되지 않는 문제가 생겼다.
예를 들어 "엘라스틱 서치"라는 제목이 있을 때 "엘라" 또는 "엘라스"로 검색해도 해당 제목의 결과가 검색되도록 하고 싶었다. 하지만 "엘라스틱" 또는 "서치"라는 사전상 의미가 있을 법한 단어로 검색했을 때에만 결과가 올바르게 나오는 것을 확인할 수 있었다.
1. 원인 살펴보기
먼저 Elasticsearch가 검색하는 방법에 대해 살펴보자.
1. Elasticsearch에서 검색은 MySQL에서 "Like"를 이용한 검색 방법과 조금 다른 점이 있다.
2. "뿌리가 깊은 나무는" 라는 문서를 "뿌리가", "깊은", "나무는"와 같이 작은 단위로 분할한다.
3. Elasticsearch는 토크나이저(Tokenizer)를 이용하여 문서를 작은 단위로 분할하며 이를 "토큰"이라고 한다.
4. Elasticsearch는 분석기(Analyzer)를 이용해 토크나이저를 정하고 필터를 이용해 분석된 데이터를 처리한다.
그럼 이제 분석기를 살펴보게 되면, 기본적으로 Elasticsearch에서 제공하는 분석기는 기본 분석기(= Standard Analyzer)를 제공하며 기본적으로 띄어쓰기로 단어를 구분한다. 그런데 이제 Nori 플러그인을 통해 분석기를 적용하게 되면 좀 더 사전적으로 의미가 있는 단어들로 단어를 구분하기 때문에 기본적인 분석기에 비해 검색 정확도가 높아질 순 있지만 여전히 위에서 말했던 문제가 존재하게 된다.
그래서 적용해본 방법이 "ngram" 플러그인이다.
2. nGram Analyzer
nGram은 문자열 중 지정된 길이의 문자들을 출력한다. 빠른 검색을 위해 사용될 용어들을 미리 분리하여 역색인(inverted index)에 저장한다.
[ 옵션 ]
- min_gram : 토큰의 최소 길이, 기본 1
- max_gram : 토큰의 최대 길이, 기본 2
- token_chars : 지정된 값에 따라 해당하는 형식의 토큰으로 인식
> letter : a,b 등 알파벳 문자
> digit : 0,1,2 등의 숫자
> whitespace : 공백과 같은 개행 문자
> punctuation : !, ., ? 과 같은 구두점
> symbol : 특수문자
[ 적용 ]
{
"index" : {
"max_ngram_diff": 5
},
"analysis": {
"analyzer": {
"korean": {
"type": "nori"
},
"ngram_analyzer" : {
"type": "custom",
"tokenizer" : "my_ngram"
},
"chosung": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"hanhinsam_chosung"
]
}
},
"tokenizer": {
"my_ngram": {
"type": "ngram",
"min_gram": "2",
"max_gram": "5",
"token_chars": [
"letter",
"digit",
"whitespace",
"punctuation"
]
}
}
}
}
ngram을 적용하고, 키워드를 "엘라"로 하여 검색했을 때 아래와 같은 결과를 얻을 수 있었다.
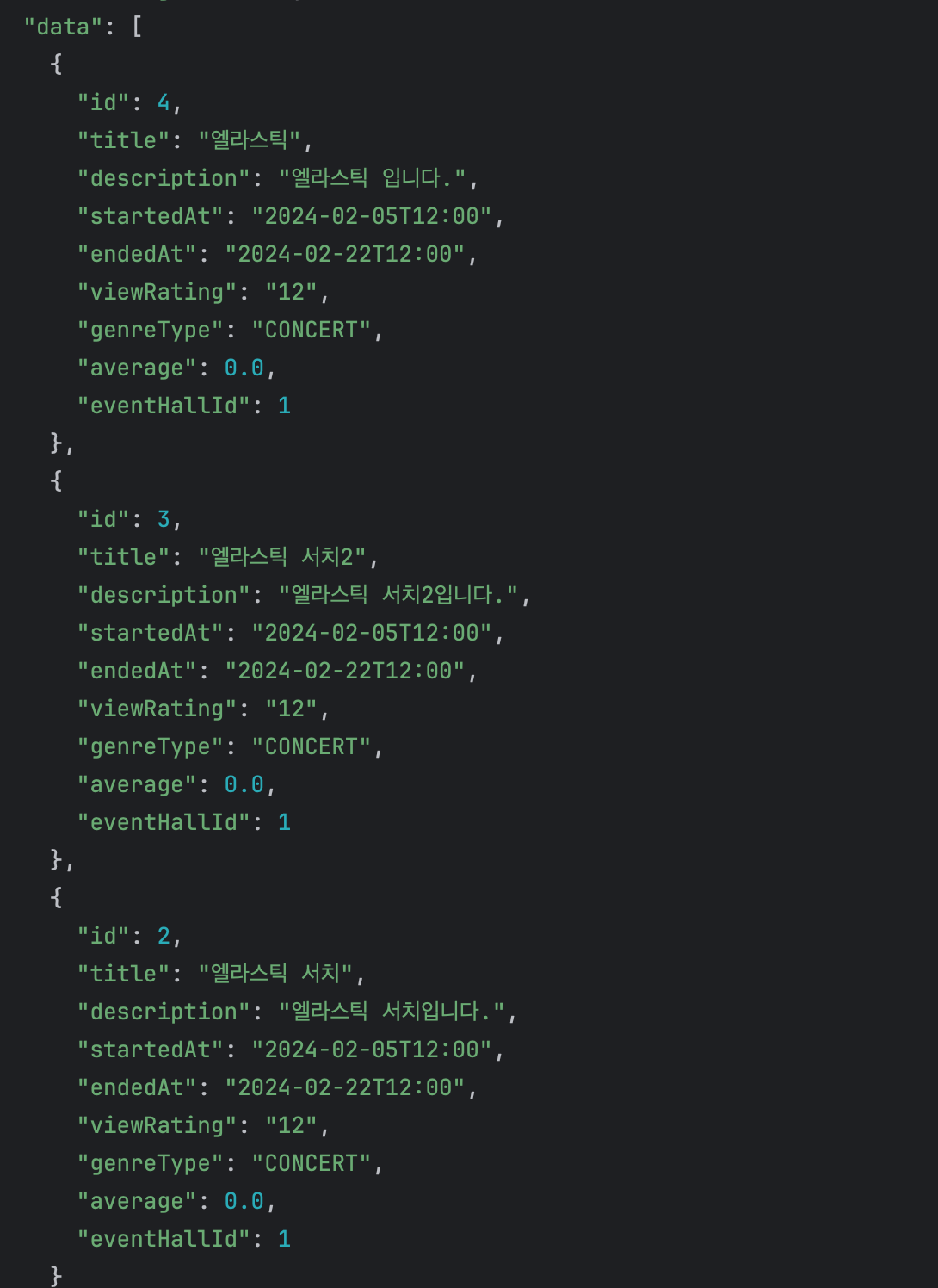
검색의 정확도가 보다 높아진 것을 살펴볼 수 있는데, ngram Token Filter 를 사용하면 저장되는 term 의 갯수가 기하급수적으로 증가한다고 한다. 따라서 일반적인 텍스트 검색에는 사용하지 않는 것이 좋으며 카테고리 목록이나 태그 목록과 같이 전체 개수가 많지 않은 데이터 집단에 자동완성 기능을 구현할 때 적합한 편이라고 하긴 한다. 우선은 적용해보았지만 뭔가 공연의 제목을 ngram Token Filter를 사용해 저장하기 때문에 term의 갯수가 크게 증가할 것 같긴 하다. 추후에 다른 방식도 고려해보면 좋을 것 같다.
<< Reference >>
[Elasticsearch] Analyzer(nori, nGram)
📋Analyzer Elasticsearch는 색인(indexing)할 때 입력된 데이터는 term 으로 추출하기 위한 과정을 거치는데 이 과정을 Analyzer 라고 합니다. Analyzer 는 하나의 Tokenizer 와 0 개 이상의 Token Filter 로 구성되어
hwangssinememory.tistory.com
Elasticsearch를 검색 엔진으로 사용하기(1): Nori 한글 형태소 분석기로 검색 고도화 하기 - 하나몬
올 4월에는 Elasticsearch(엘라스틱서치) 검색엔진을 이용한 회사 웹사이트의 검색 품질을 개선하는 작업을 했습니다. 기존의 검색 기능은 MySQL의 ‘Like’ 기능을 이용한 방식을 사용했는데, 이는
hanamon.kr