
0. OverView
2023.12.15 ~ 2024.01.12(4주) 동안 "인터파크 티켓" 사이트를 타겟으로 한 클론 코딩을 진행하게 되었습니다. 팀원 한명과 함께 "공연" 도메인을 맡게 되었고 핵심 기능으로 "검색 기능"을 선정하여 구현하고자 하였습니다. 클론 코딩을 진행한 "인터파크 티켓" 사이트는 찾고자 하는 키워드로 검색을 하면 빠른 속도로 검색기능을 제공하는 것을 확인할 수 있었고, 검색 기능을 어떤 방식으로 구현하면 좋을까를 고민하다가 엘라스틱서치를 도입하여 RDB만을 사용하여 구현했을 때 보다 성능적인 면에서 개선한 사례를 기록해보려고 합니다.
1. 검색 기능 분석

먼저 저와 팀원은 "인터파크 티켓"의 검색 기능을 분석하였습니다.
- 키워드로 검색하면 공연의 제목 뿐만 아니라 내용, 장르까지 함께 검색됨을 확인할 수 있었습니다.
- 부가적으로 유사어, 초성 검색을 통해서도 검색할 수 있었습니다.
- 지연시간은 300ms 이내로 확인할 수 있었습니다.
기능적으로나, 성능적으로 RDB와 JPA만을 사용하여 검색기능을 구현한다는 것은 꽤나 까다로웠습니다. 특히나 유사어, 초성 관련 검색 기능은 JPA만으로 구현하기가 매우 어려웠고 Like문을 이용해 검색 기능을 구현할 경우, 그 특성 상 Full Scan 방식으로 동작하기 때문에 데이터가 많거나 한 공연 내의 공연 내용이 100줄이 넘어가게 된다면 굉장한 시간을 초래하여 성능 저하가 발생할 것 이라고 생각하게 되었습니다.
따라서 검색 기능을 "제목+내용+장르"안에 포함되는 검색 키워드를 빠른 시간안에 찾을 수 있는 기술로 Elasticsearch를 적용하게 되었습니다.
2. Elasticsearch, 왜 더 빠를까 ?

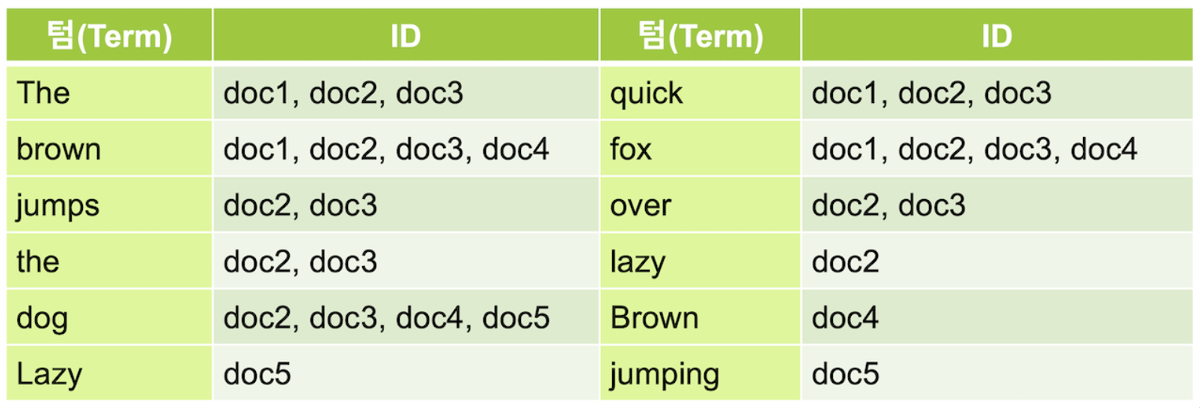
책에서 찾고자 하는 단어를 맨 뒤의 색인을 통해 몇 페이지인지 바로 알아내는 것이 빠를까? 아니면 책을 펼쳐서 처음부터 끝까지 살펴보는 것이 빠를까 ? 전자가 훨씬 빠를 것이라는 것을 생각해볼 수 있습니다.
먼저, RDB에서 Like 검색을 사용하게 되면 데이터가 늘어날수록 검색해야 할 대상이 늘어나 시간도 오래 걸릴 뿐만 아니라 row 안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가 느립니다.
하지만 엘라스틱서치는 원문에서 색인어(Term)를 추출하고 색인어수(문서 빈도)를 카운트하고 정렬후 색인어별 역색인 벡터를 만드는 역색인(Inverted Index) 구조로 데이터를 저장하기 때문에 특정 단어가 어떤 인덱스(문서)에 저장되어 있는지 바로 확인할 수 있습니다.
출처 : 엘라스틱 서치 가이드북
3. 검색 기능 구현
[ JPA ]
@Override
public Page<EventResponse> getEventsByKeyword(EventKeywordSearchDto eventKeywordSearchDto) {
Pageable pageable = eventKeywordSearchDto.pageable();
int offset = pageable.getPageNumber() * pageable.getPageSize();
List<EventResponse> content = jpaQueryFactory.selectFrom(event)
.where(
containsKeyword(eventKeywordSearchDto.keyword()), // 키워드 검사
isGenreType(eventKeywordSearchDto.genreType()) // 장르 필터
)
.offset(offset)
.limit(pageable.getPageSize())
.fetch()
.stream()
.map(EventResponse::of)
.toList();
JPAQuery<Long> countQuery = jpaQueryFactory.select(event.count())
.from(event)
.where(
containsKeyword(eventKeywordSearchDto.keyword()),
isGenreType(eventKeywordSearchDto.genreType())
);
return PageableExecutionUtils.getPage(content, pageable, countQuery::fetchOne);
}
private BooleanBuilder containsKeyword(String keyword){
BooleanBuilder booleanBuilder = new BooleanBuilder();
if(keyword == null) {
return null;
}
booleanBuilder.or(event.title.contains(keyword));
booleanBuilder.or(event.description.contains(keyword));
return booleanBuilder;
}
// 생략먼저 JPA, QueryDsl과 Like문으로 제목, 장르에서 키워드를 검색할 수 있는 검색 쿼리를 작성해주었습니다.
[ Elasticsearch ]
public Page<EventDocumentResponse> findByKeyword(EventKeywordSearchDto eventKeywordSearchDto) {
Pageable pageable = eventKeywordSearchDto.pageable();
NativeQuery query = getKeywordSearchNativeQuery(eventKeywordSearchDto).setPageable(pageable);
SearchHits<EventDocument> searchHits = elasticsearchOperations.search(query, EventDocument.class);
log.info("event-keyword-search, {}", eventKeywordSearchDto.keyword());
return SearchHitSupport.searchPageFor(searchHits, query.getPageable()).map(s -> {
EventDocument eventDocument = s.getContent();
return EventDocumentResponse.of(eventDocument);
});
}
private NativeQuery getKeywordSearchNativeQuery(EventKeywordSearchDto eventKeywordSearchDto) {
NativeQueryBuilder queryBuilder = new NativeQueryBuilder();
Query query = QueryBuilders.match()
.query(eventKeywordSearchDto.keyword())
.field("keyword_text")
.build()._toQuery();
List<Query> filterList = new ArrayList<>();
if (eventKeywordSearchDto.genreType() != null) {
List<FieldValue> fieldValues = eventKeywordSearchDto.genreType().stream()
.map(FieldValue::of)
.toList();
TermsQueryField termsQueryField = new TermsQueryField.Builder()
.value(fieldValues)
.build();
Query genreFilterQuery = QueryBuilders
.terms()
.field("genreType")
.terms(termsQueryField)
.build()._toQuery();
filterList.add(genreFilterQuery);
}
if (eventKeywordSearchDto.startedAt() != null) {
Query startedAtFilterQuery = QueryBuilders
.range()
.field("startedAt")
.gte(JsonData.of(eventKeywordSearchDto.startedAt()))
.build()._toQuery();
filterList.add(startedAtFilterQuery);
}
if (eventKeywordSearchDto.endedAt() != null) {
Query endedAtFilterQuery = QueryBuilders
.range()
.field("endedAt")
.gte(JsonData.of(eventKeywordSearchDto.endedAt()))
.build()._toQuery();
filterList.add(endedAtFilterQuery);
}
Query boolQuery = QueryBuilders.bool()
.filter(filterList)
.must(query)
.build()._toQuery();
return queryBuilder.withQuery(boolQuery)
.build();
}엘라스틱서치도 마찬가지로 제목, 장르, 설명에서 키워드를 검색할 수 있는 쿼리를 작성해주었습니다. 이때 좀 더 상세하고 정확한 검색 기능을 위해 음절 단위의 검색을 구현하고자 ngram 분석기를 적용하고, 초성 검색을 위한 추가 플러그인을 적용해주었습니다.
4. 트러블 슈팅
데이터를 실제로 넣고, 테스트하는 과정을 진행하려던 그 때 문제가 발생했습니다.
org.springframework.dao.DataAccessResourceFailureException: 50,000 milliseconds timeout on connection http-outgoing-0 [ACTIVE];
예외의 내용은 Elasticsearch와의 연결에서 시간 초과가 발생했음을 짐작할 수 있었고 대량으로 데이터를 Elasticsearch에 추가해주는 과정에서 발생했습니다. 데이터를 빠르게 넣어주기 위해 bulk insert를 사용하였는데 어플리케이션에서 엘라스틱 서치로 한 번의 요청 당 몇 백건의 데이터(도큐먼트)를 엘라스틱 서치에 저장하게 됩니다.

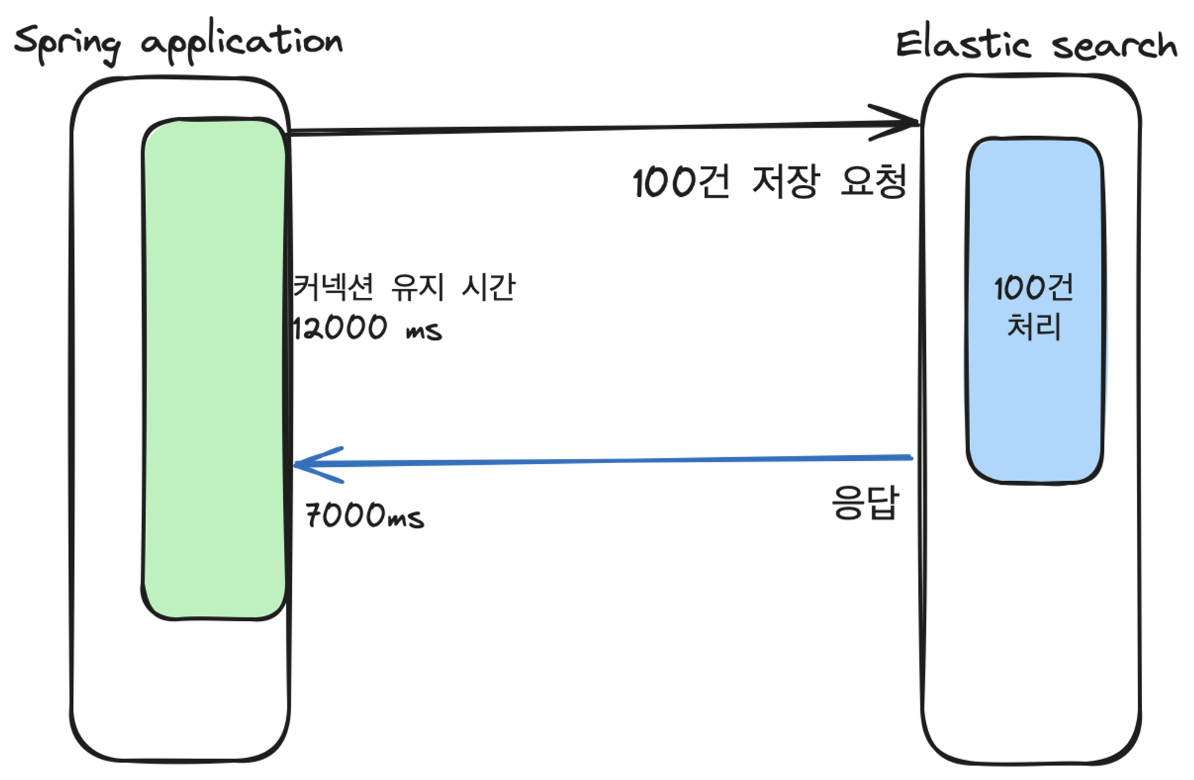
그런데, 일정 시간 안에 응답을 받지 못하게 되었을 때 timeout 오류가 발생한다고 생각하게 되었고 처음엔 엘라스틱 서치의 설정이 잘못 되었다고 판단했으나 결과적으로는 Spring Data Elasticsearch의 Config 파일에서 연결 풀의 구성 중 커넥션 유지시간을 조정하여 해결할 수 있었습니다.
@Configuration
public class ElasticSearchConfig extends ElasticsearchConfiguration {
@Override
public ClientConfiguration clientConfiguration() {
return ClientConfiguration.builder()
.connectedTo("localhost:9200")
.withConnectTimeout(120000) // 커넥션 유지 시간
.withSocketTimeout(120000)
.build();
}
}
5. 성능 측정 - 더미 데이터 삽입
우선 성능 측정에 앞서, "공공데이터포털" 사이트에서 공연 관련 "전국공연행사정보표준데이터"를 csv 파일 형식으로 다운 받아 MySQL과 Elasticsearch에 각각 대략 10만건 정도의 데이터를 Bulk Insert를 통해 데이터를 넣어주도록 했습니다.
[ MySQL ]
@Service
@RequiredArgsConstructor
@Transactional
public class CsvReader {
private final EventRepository eventRepository;
private final EventSearchQueryRepository eventSearchQueryRepository;
private final EventHallRepository eventHallRepository;
private final JdbcTemplateEventRepository jdbcTemplateEventRepository;
public void saveEventCsv(String filepath) {
try {
String filePath = Paths.get(filepath).toString();
EventHall eventHall = eventHallRepository.findById(1L)
.orElseThrow(() -> new EventException(EVENT_HALL_NOT_FOUND));
try (BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream(filePath), "EUC-KR"))) {
List<Event> events = br.lines()
.skip(1)
.map(line -> line.split(","))
.map(data -> new EventCreateRequest(
data[0], data[2], 100,
LocalDateTime.now(), LocalDateTime.now().plusDays(10),
null, GenreType.MUSICAL,
LocalDateTime.now(), LocalDateTime.now().plusDays(10), 1L)
.toEntity(eventHall))
.collect(Collectors.toList());
jdbcTemplateEventRepository.bulkSave(events);
} catch (IOException e) {
throw new RuntimeException("Failed to load file", e);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}- 기존 데이터 삽입 시 JPA의 saveAll() 메서드를 통해 저장하도록 했지만 저장속도가 매우 느리고 쿼리 수가 굉장히 많았습니다.
- JdbcTemplate을 이용하여 Insert 쿼리가 한 번에 나가도록 Bulk Insert를 구현하여 데이터를 삽입하는 방식으로 변경했습니다.
[ Elasticsearch ]
// CsvReader
public void saveAllDocument() {
int batchSize = 100;
List<Event> events = eventRepository.findAll();
List<EventDocument> documents = new ArrayList<>();
for (int i = 0; i < events.size(); i += batchSize) {
List<Event> batchEvents = events.subList(i, Math.min(i + batchSize, events.size()));
batchEvents.forEach(e -> documents.add(EventDocument.from(e)));
eventSearchQueryRepository.bulkInsert(documents);
documents.clear();
}
}
-------------------------------------------------------------------------------------
// elasticSearchQueryRepository
public <T> void bulkInsert(List<T> documents) {
try {
int chunkSize = 50;
List<IndexQuery> insertQueries = new ArrayList<>();
for (int i = 0; i < documents.size(); i += chunkSize) {
List<T> chunk = documents.subList(i, Math.min(i + chunkSize, documents.size()));
for (T document : chunk) {
IndexQuery indexQuery = new IndexQueryBuilder()
.withObject(document)
.build();
insertQueries.add(indexQuery);
}
elasticsearchOperations.bulkIndex(insertQueries, IndexCoordinates.of("events"));
insertQueries.clear();
}
} catch (Exception e) {
throw e;
}
}- 엘라스틱서치 역시 Bulk Insert를 이용하여 데이터를 넣어주었습니다.
- 메모리 부족, 네트워크 지연 등을 피하고자 chunkSize로 나누어 작은 묶음들로 인덱싱을 진행하였습니다.

이렇게 약 10만개의 데이터를 MySQL과 Elasticsearch에 저장해주고, 그 결과를 확인할 수 있었습니다.
6. 성능 측정 - JPA vs Elasticsearch
데이터도 다 넣어주었기 때문에 마지막으로 JPA와 Elasticsearch의 검색 성능을 비교 해보도록 하겠습니다. 검색 성능 측정은 각각 ExecutionTime을 비교할 수 있도록 AOP 어노테이션을 이용하여 진행하였습니다.
[ 키워드 - 스프링으로 검색 ]

- JPA 측정 시간(ms) : 252810541ns ÷ 1000000 = 252ms
- Elasticsearch 측정 시간(ms) : 110791708ns ÷ 1000000 = 110ms
- 약 129% 성능 향상
[ 키워드 - 클래식으로 검색 ]

- JPA 측정 시간(ms) : 260847542ns ÷ 1000000 = 260ms
- Elasticsearch 측정 시간(ms) : 98097125 ÷ 1000000 = 98ms
- 약 165% 성능 향상
→ 전반적으로 엘라스틱서치 키워드 검색의 검색 성능이 JPA에 비해 높은 성능을 보여주는 것을 확인할 수 있었습니다.
마치며
도커를 통해 ELK 스택을 구성하거나, Spring Data Elasticsearch로 쿼리 코드를 작성할 때 버전별로 사용법이 상이하고 관련 자료가 많지 않아 어려움이 많았지만 그럼에도 엘라스틱서치를 도입해 기능적, 성능적으로 보다 개선점을 도출해낼 수 있었습니다.
10만개의 데이터가 결코 적은 수의 데이터는 아니지만 훨씬 더 많은 데이터를 넣었을 때 그 차이는 분명 더 확실하게 확인할 수 있을 것 같습니다.