
프로젝트를 진행하면서, 웹소켓을 통한 실시간 메세지를 전달해야 하다보니 메세지 브로커를 사용하게 되었고 기존에는 인메모리 브로커를 사용하여 구현을 했습니다.
그런데, 인메모리 브로커가 아래와 같은 단점들이 존재한다는 것을 알게 되었습니다.
1. 세션을 수용할 수 있는 크기가 제한되어 있다.
2. 장애 발생 시 메세지가 유실될 가능성이 높다.
3. 따로 모니터링 하는 것이 불편하다.
따라서 STOMP 전용 외부 브로커를 사용하고자 했고, 가장 많이 사용되는 RabbitMQ와 Kafka 중 무엇을 사용할 지 고민하다가 Kafka를 사용하기로 결정했습니다. (왜 Kafka를 선정했는지는 또 다른 포스팅에서 따로 작성하도록 하겠습니다.)
사용하는 김에 어떠한 구성요소들이 있고 개념이 무엇인지 인지하고 사용하기 위해 개념을 정리해보고자 합니다.
1. 카프카(Kafka) ?
kafka는 실시간으로 스트리밍 데이터를 게시, 구독, 저장 및 처리할 수 있는 '분산형 데이터 스트리밍 플랫폼'입니다.
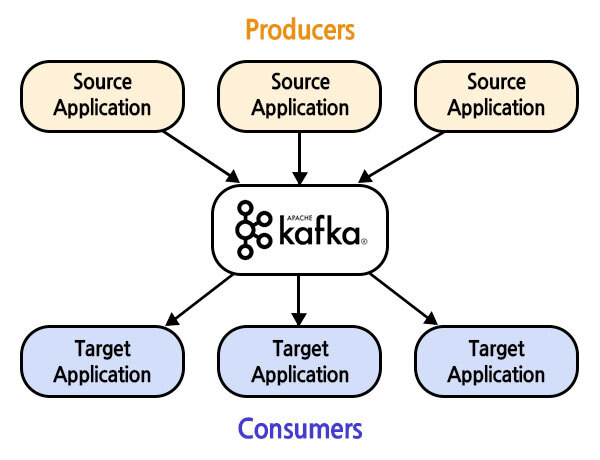
기존의 직접적인(end-to-end) 연결 방식의 아키텍처는 데이터 연동의 복잡성이 높고 확장이 어려운 구조인 반면, Kafka를 사용하면 보내는 쪽에서 Kafka로 메세지를 보내고, 받는 쪽에서 그 메세지를 누가 생성하고 보냈는지에 상관없이 단순히 메세지 자체를 가져와 처리할 수 있게 됩니다. (text, json, xml, java의 Object등 다양한 데이터 포맷 사용 가능)
이렇게 '확장이 용이한 시스템'이라는 점과 함께 '클러스터링에 의한 고가용성'이라는 특징, '낮은 지연(Latency)'과 높은 '처리량 (Throughput)'으로 인해 Kafka를 사용하면 많은 데이터를 효과적으로 처리할 수 있습니다.
2. 카프카 구조
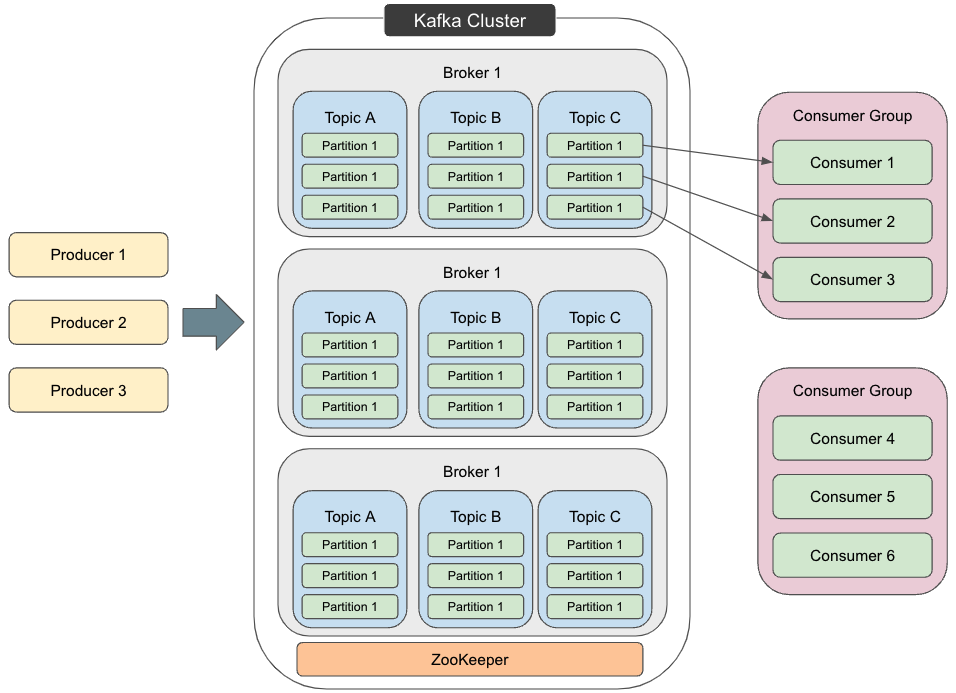
카프카 아키텍처 구조를 살펴보면, Kafka로 데이터를 보내는 'Producer' 즉, 생산자와 Kafka에서 데이터를 가져오는 'Consumer' 라는 소비자가 있으며 (producer, consumer는 각기 다른 프로세스에서 비동기로 동작), 'Kafka Cluster'를 중심으로 프로듀서와 컨슈머가 데이터를 발행 및 구독하는 'Pub/Sub' 모델로 동작하고 있는 것을 확인할 수 있습니다.
이런 방식으로 인해 Kafka는 분산 환경에 특화되어 있다는 특징 또한 가지고 있습니다.
1. 카프카 클러스터 (Kafka Cluster)

실제 서비스에서 사용되는 카프카는 고가용성을 위해 '여러 개의 kafka 서버와 Zookeeper로 구성된 클러스터 구조'로 사용되는데 일반적으로 3개 이상의 kafka 서버(Broker)로 구성되기 때문에 broker에 저장된 메세지를 다른 브로커에게 공유하고 하나의 브로커에 문제가 생겼을 때, 다른 브로커로 그 역할을 대체해 시스템을 정상 유지하는 방식으로 동작합니다.
'Zookeeper'는 분산 어플리케이션의 데이터 관리 기능을 가지고 있으며, 여러 개의 Broker들을 컨트롤 해주는 역할을 수행합니다. 따라서 Kafka는 Zookeeper 없이 동작할 수 없습니다. (multi broker들 간의 정보 변경 공유 및 동기화 등을 수행)
각각의 카프카 서버를 Kafka Broker라고 하며 (또는 bootstrap server), N개의 Broker 중 1대는 리더의 역할을 수행
2. 토픽(Topic) 및 파티션(Partition)
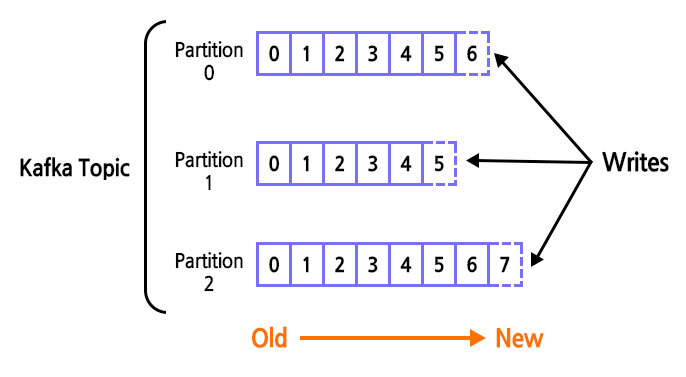
'Topic'은 데이터가 들어갈 수 있는 공간으로 여러 개의 토픽이 생성될 수 있는데 topic은 카프카 클러스터에서 데이터를 관리할 때 기준이 되는 요소가 된다고 합니다. 또한 각각의 토픽은 이름을 가지며, 목적에 따라 무슨 데이터를 담는지 명시하면 추후 유지보수 시 편리하게 관리할 수 있습니다.
즉, Broker 내의 Message의 보관 영역을 의미하고 같은 분류의 Message는 같은 Topic에 보존되는 구조입니다. 각 Producer는 특정 Topic에 대해 메세지를 보내고, 각 Consumer는 특정 Topic에 Message를 가져와 처리합니다. Topic에 저장된 Message는 필요할 때, 다시 읽을 수 있습니다.
(1) 각각의 Topic은 1개 이상의 'Partition'으로 구성
- partition은 토픽 안에서 데이터를 분산 처리하는 단위로 볼 수 있고, 첫 번째 파티션은 0번부터 시작됩니다. 하나의 파티션은 큐(Queue)와 같이 파티션 끝에서부터 데이터가 쌓이게 되고, consumer는 가장 오래된 순으로 데이터를 가져가게 됩니다.
(2) Kafka는 Consumer가 데이터를 가져가도 파티션에 있는 데이터는 삭제되지 않는다.
- Kafka는 동일 데이터에 대해 여러 번 처리할 수 있다는 특징이 있는데 데이터가 삭제되지 않기 때문입니다. 이것이 카프카를 사용하는 이유 중 하나이기도 합니다.
3. 프로듀서(Producer), 컨슈머(Consumer)

'Producer'는 Topic에 저장할 데이터를 생성하고 전송하는 역할을 합니다. 데이터를 전송할 때 Key 설정을 통해 Topic의 Partition을 지정할 수 있습니다.
'Consumer'는 토픽 내부의 파티션에 저장된 데이터를 가져오는 역할을 합니다. 데이터를 가져오는 것을 Polling이라고 하는데, 파티션으로부터 데이터를 가져오면서 Offset 위치를 기록하는 역할도 합니다.
offset이란 파티션에 있는 데이터의 고유한 번호를 뜻하며, consumer가 offset을 저장함으로써 데이터를 어디까지 읽었는지 확인할 수 있고, 저장된 offset이 있기 때문에 consumer가 멈추는 상황이 발생하더라도 재시작되었을 때 중지된 시점부터 데이터를 읽어올 수 있습니다.
하나의 토픽에 대한 consumer 개수는 partition 개수보다 적거나 같아야 하는데, 그 이유는 컨슈머가 더 많을 경우 더 이상 할당될 파티션이 없기 때문에 남은 consumer는 동작하지 않게 된다는 점은 알아두어야 합니다.
<< 참고 자료 >>
Apache Kafka 기본 개념 총정리
카프카의 탄생 카프카 도입 전의 단점을 파악하여 카프카가 왜 탄생했는지에 대해서 알아봅시다. 카프카 도입 전 1) 일반적으로 데이터를 생성하는 '소스 애플리케이션'과 생성된 데이터가 적재
devfunny.tistory.com
Apache Kafka 주요 개념 정리 (Cluster, Topic, Producer, Consumer)
kafka 주요 개념 정리(cluster, topic, producer, consumer) 1. 카프카(Kafka)란? Kafka는 링크드인(Linked-in)에서 처음 개발되어 2011년 오픈소스화 된 솔루션인데요. 실시간으로 스트리밍 데이터를 게시, 구독, 저
wildeveloperetrain.tistory.com