
0. overview
지금까지 공부하면서 또는 프로젝트를 경험하면서 항상 확장성을 고려한 설계에 관심을 가지고는 있었지만 막상 대용량 트래픽 처리를 위해서 시스템 설계 방식에 대한 방법이 명확히 떠오르지 않았고, 이번 기회에 어떤 방버들이 있는지 정리해보고자 한다.
WAS 서버를 세팅하고 서비스를 구축했다. 간단히 구축한 시스템 구조는 아래와 같다.
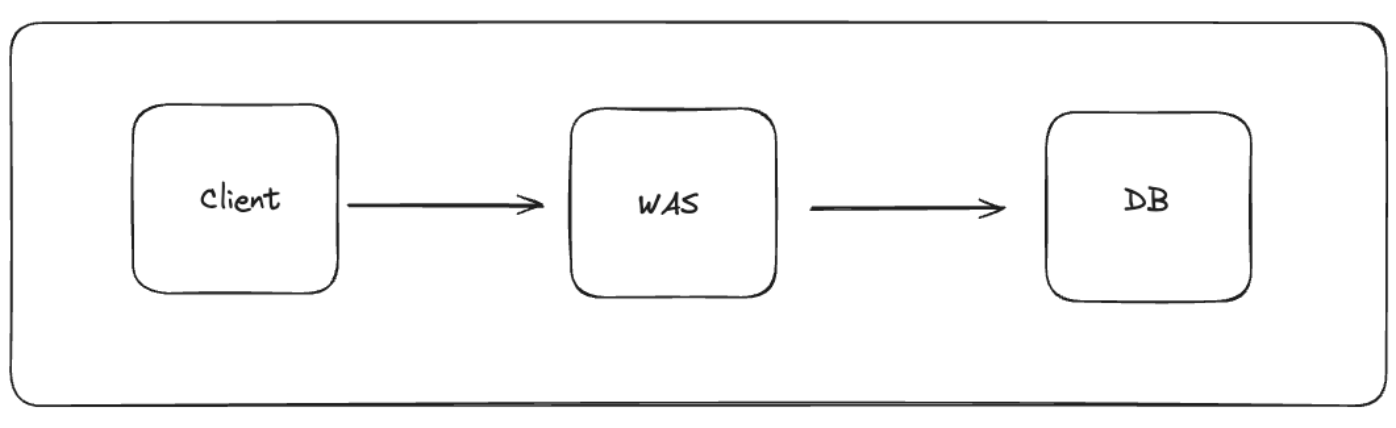
사용자 증가

사용자가 증가함에 따라, WAS의 성능적인 제한으로 점점 느려지는 현상이 발생할 수 있다. 따라서 WAS 서버를 Scale-Up을 통해 수직적 확장을 진행하여 느려지는 현상을 처리할 수 있다.
수직적 확장의 한계
물론, 수직적 확장을 통해 어느 정도 성능 향상을 기대할 수 있지만 결국 트래픽이 계속해서 증가한다면 아무리 수직적 확장을 해도 한계에 도달하기 마련이다.
장비의 성능만 업그레이드 하는 것은 한계가 있을 뿐더러, 그 비용이 무척이나 비싸다.
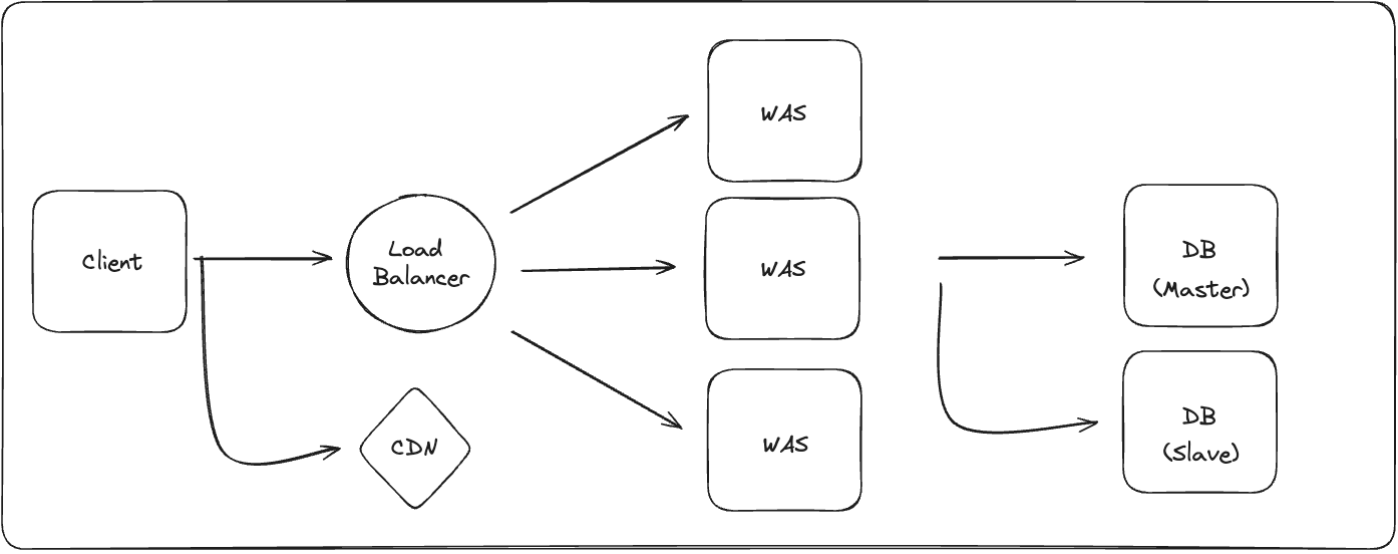
따라서 어느 정도 scale-up을 진행했다면, 수평적 확장을 위한 scale-out을 통해 구성할 수 있도록 하자.

수직적 확장 단계와 차이점은 WAS가 추가적으로 생겼고 이는 한 그룹으로 묶여있다. 그리고 그 앞에 LoadBalancer를 추가하여 여러 대의 WAS에 골고루 트래픽을 분산 처리한다.
DB 이중화

이전 단계에서 수평적 확장을 통해 WAS의 개수를 늘리면서 성능 향상을 이뤄낼 수 있었다.
다음 단계로, 시스템에서 부하를 가장 많이 받는 곳은 I/O가 발생하는 DB인데, DB를 확장하는 방법 중 하나인 Replication을 활용하여 Master와 Slave로 나누고 쓰기 작업은 Master, 읽기 작업은 Slave로 처리하도록 분산한다.
이렇게 서비스하면 두 대중 한 대의 DB 인스턴스에 장애가 발생했을 때 나머지 한대로 서비스가 가능하다.
Master DB가 장애가 나는 경우엔 Slave 중에 하나를 Master DB로 전환한다.
[ 주의할 점 ]
- Master 1대에 여러 대의 Slave를 설정하는 경우에 Master 데이터를 Slave로 복사하는데 지연 생김
Static 파일 분리
서비스 운영 시 정적 파일을 제공해야 하는 경우가 꽤나 존재한다.
- Front-end 코드 파일
- 이미지 파일 등
정적 파일은 반드시 WAS에서 제공해야 하는 것이 아니기 때문에 서버 트래픽의 부담을 줄이기 위해 정적 파일은 AWS CloudFront 등을 이용해 CDN을 통해 서비스 할 수 있다.
위 그림과 같이 구성하여 CDN을 통해 정적 파일을 제공하면 사용자 입장에서는 더 빠르게 서비스를 이용할 수 있고, 운영 측면에서는 Back-end 코드와 Front-end 코드를 분리할 수 있는 장점이 있다.
Memory DB

추가적으로 WAS와 DB 사이에 Memory DB를 둘 수 있다.
예를 들어 Redis가 있는데, 메모리를 사용해 DB 데이터를 캐시 하게 되면 엄청 빠른 속도로 조회되는 것을 경험할 수 있다. (비용이 증가하긴함)
주의해야할 점은 DB의 모든 데이터를 cache하면 효율이 떨어진다.
최대한 hits가 많이 생길 수 있도록 자주 조회하는 데이터를 cache 하는 것이 효율적이다.
MSA로 전환
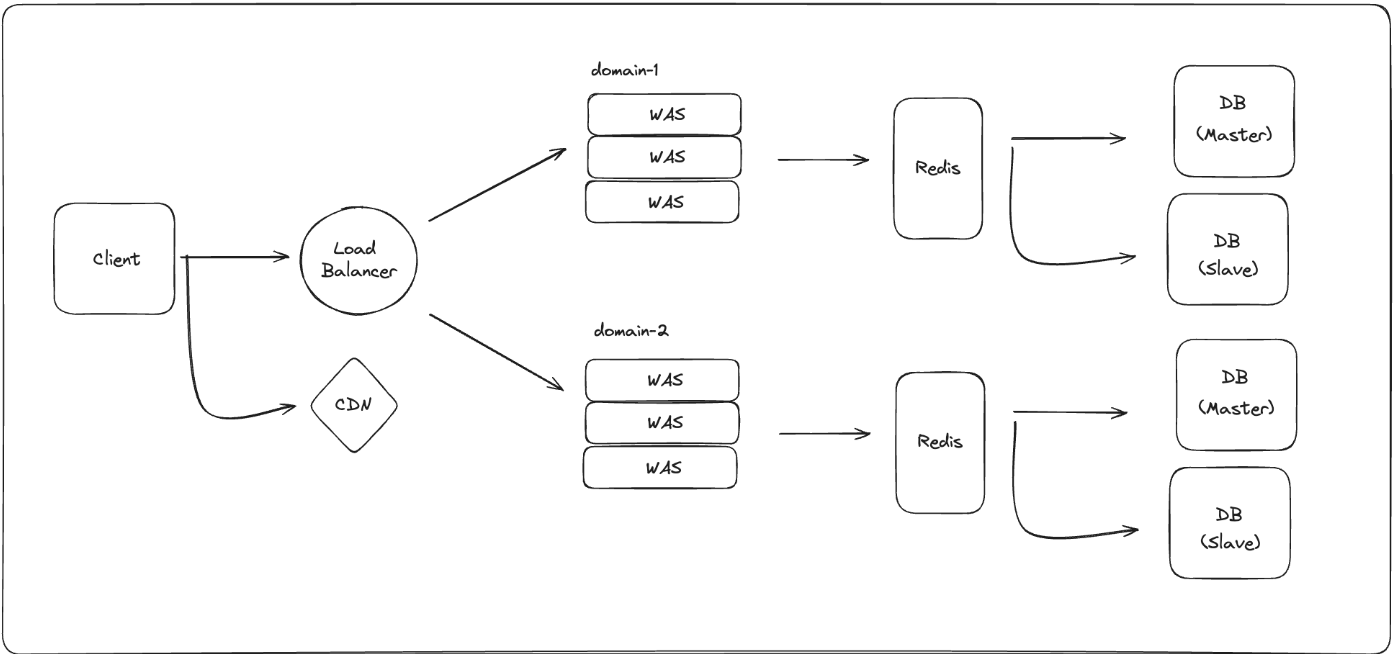
여전히 트래픽이 증가함에 따라 요청에 대한 WAS 자체를 분리하는 것은 부담스러울 수 있다.
이를 개선할 수 있는 방법으로는 MSA 아키텍처가 존재하는데 도메인별로 혹은 하위 도메인으로 서버를 분리하고 각 서버는 본인의 DB만을 사용한다.
예를 들어 한 서비스에 5개 이상의 도메인이 있을 때, MSA로 전환하면 한 개의 서버가 처리하는 양은 기존보다 꽤나 많이 줄어들 것이다.
CQRS
> CQRS ?
> : CQRS란 명령과 쿼리의 역할을 구분하는 것이다. CRUD에서 CUD(Command)와 R(Query)의 책임을 분리하는 것이 바로 CQRS이다. DB를 사용하면서 트랜잭션의 ACID를 보장하기 위해 노력했으나 MSA 구조가 많이 채택되면서 도메인 별로 개발하다보니 DB를 분리하고 그 문제가 도드라지게 되었다. 이런 변경 가능성과 동시성 문제 등을 R과 CUD를 구분함으로써 얻는 이점을 설명하는 것이 CQRS 패턴이다.
기존의 CQRS는 Replication을 통해 Slave와 같은 분리를 통해 읽기 전용 DB를 분리하는 형식으로 적용할 수 있었다. 그러나 단순 모델의 분리로는 성능 문제와 더불어 동기화 방식의 고민이 남아있다.
따라서 더 높은 수준의 CQRS 패턴은 Event Sourcing과 함께, Queue(AWS SQS, RabbitMQ, Kafka)와 같은 Message Queue를 이용하여 비동기적으로 데이터를 쓰고 읽어오는 형태를 취한다.
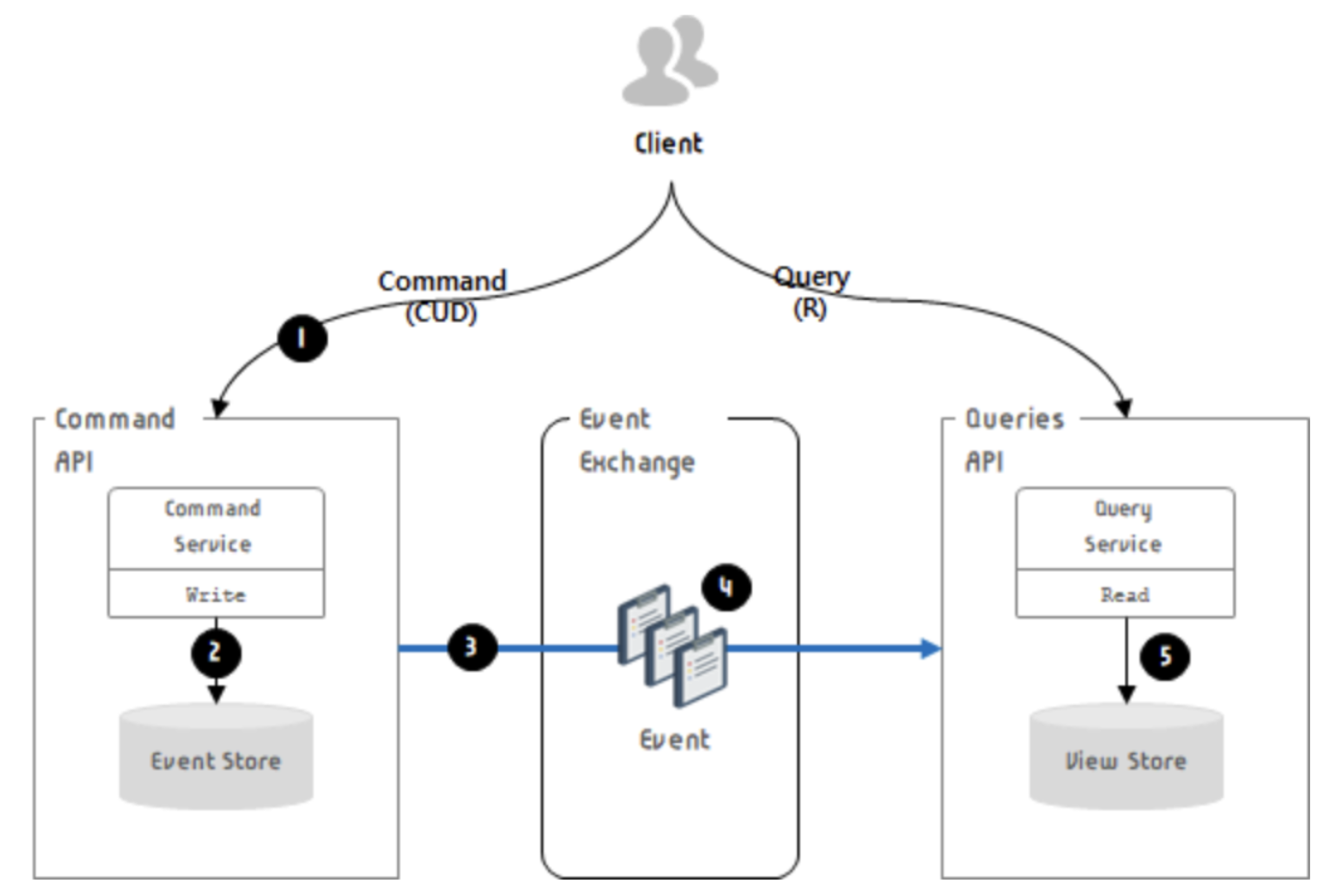
이벤트 소싱이란 Application 내의 모든 Activity를 이벤트로 전환해서 이벤트 스트림(Event Stream)을 별도의 Database에 저장하는 방식을 의미한다.
기존 ORM은 변경 사항이 업데이트 되면 이전의 내역은 사라졌기 때문에 변경 내역을 관리하는 용도로는 이벤트 소싱이 더욱 적합하다.
CQRS 구조 적용 후 서비스의 아키텍처는 아래와 같이 구성될 수 있다.

<참고 자료>
https://kyungyeon.dev/posts/96
https://velog.io/@_koiil/MSA-CQRS-%ED%8C%A8%ED%84%B4-%EC%A0%81%EC%9A%A9%ED%95%98%EA%B8%B0