
Index ?
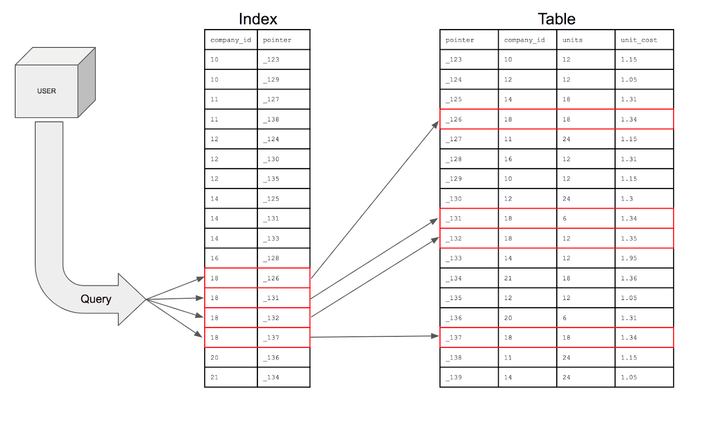
인덱스란 데이터베이스 테이블의 검색 속도를 향상 시켜주는 자료구조라고 할 수 있다. 특정 컬럼에 인덱스를 생성하면 해당 컬럼의 데이터들을 정렬해서 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장한다. 인덱스를 이용하여 쿼리문을 작성하면 옵티마이저에서 판단하여 생성된 인덱스를 탈 수 있다.
옵티마이저
: 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성해주는 DBMS의 핵심
그렇다면 Index를 왜 쓸까 ??
인덱스의 가장 큰 특징은 데이터들이 정렬 되어있다는 점이다. 이 특징으로 조건 검색이라는 부분에서 큰 장점이 된다.
1) 조건 검색 WHERE절의 효율성
테이블 내의 데이터가 쌓이면 테이블의 튜플은 내부적으로 순서가 뒤죽박죽 저장이 되고 이를 WHERE 절로 데이터를 찾게 되면 레코드의 처음부터 끝까지 다 읽어서 검색 조건과 비교한다. 반면 인덱스 테이블은 데이터가 정렬되어 있기 때문에 해당 조건에 맞는 데이터들을 빠르게 찾아낼 수 있다.
2) 정렬 ORDER BY 절의 효율성
인덱스를 사용하면 ORDER BY에 의한 정렬(Sort) 과정을 피할 수 있다. ORDER BY는 굉장히 부하가 많이 걸리는 작업이기 때문에 인덱스를 사용하면 이러한 작업을 하지 않아도 된다.
3) MIN, MAX의 효율적인 처리
정렬되어 있기 때문에 레코드의 시작 값과 끝 값 한 건씩만 가져오면 되기 때문에 MIN과 MAX의 처리가 굉장히 효율적이다.
그렇다면 Index의 단점은 ??
인덱스의 가장 큰 문제점은 정렬된 상태를 계속 유지시켜줘야 한다는 점이다. 레코드 내의 데이터 값이 바뀌는 부분이라면 악영향을 미칠 수 있다.
1) 인덱스는 DML에 취약
INSERT, UPDATE, DELETE를 통해 데이터가 추가되거나 값이 바뀌면 인덱스 테이블 내에 데이터 값들을 다시 정렬해야 한다.
2) 무조건 인덱스 스캔이 좋은 것은 아니다.
데이터의 개수가 100개, 1000개, 100000... 개 라면 인덱스 스캔이 좋을 수 있다. 그러나 데이터가 1개이거나 2개 이런식으로 굉장히 작은 개수의 데이터가 있는 테이블이라면 인덱스 스캔보다 풀 스캔이 더 효율적일 것이다.
3) 속도 향상을 위해 인덱스를 많이 만드는 것은 좋지 않다.
인덱스를 관리하려면 데이터베이스의 약 10%에 해당하는 저장공간이 추가로 필요하며 무턱대고 인덱스를 만들어선 안된다. 즉, 속도 향상에 비해 단점들의 COST를 비교하여 인덱스를 만들지 말지를 정해야 한다.
참고 자료
https://choicode.tistory.com/27
[DB] 데이터베이스(DB) 인덱스(Index) 란 무엇인가?
들어가면서.. DB를 사용하면서 데이터의 양(row)에 따라 실행 결과의 속도가 차이가 나는 것을 알고 있었다. 특히 데이터의 양이 증가할수록 실행 속도는 느려지고, JOIN이나 서브 쿼리 사용 시 곱
choicode.tistory.com