
DDL
- DB를 구축하거나 수정할 목적으로 사용하는 언어
- CREATE : SCHEMA , DOMAIN, TABLE, VIEW, INDEX를 정의
- ALTER : TABLE 에 대한 정의를 변경하는데 사용함
- DROP : SCHEMA, DOMAIN, TABLE, VIEW, INDEX를 삭제
CREATE DOMAIN
- 도메인을 정의하는 명령문
- 표기형식
CREATE DOMAIN 도메인명 [AS] 데이터_타입
[DEFAULT 기본값]
[CONSTRAINT 제약조건명 CHECK (범위값)];
ex) '성별'을 '남' 또는 '여'와 같이 정해진 1개의 문자로 표현되는 도메인 SEX를 정의하는 SQL문 작성
CREATE DOMAIN SEX CHAR(1)
DEFAULT '남'
CONSTRAINT VALID-SEX CHECK(VALUE IN('남', '여'));
CREATE TABLE
- 테이블을 정의하는 명령문
- 표기 형식
CREATE TABLE 테이블명
(속성명 데이터_타입 [DEFAULT 기본값][NOT NULL], ...
[,PRIMARY KEY (기본키, 속성명...)]
[,UNIQUE(대체키, 속성명 ...)]
[,FOREIGN KEY(외래키_속성명,...)]
REFERENCES 참조테이블 (속성명 ...)[
[ON DELETE 옵션]
[ON UPDATE 옵션]
[,CONSTRAINT 제약조건명][CHECK (조건식)];
ex) <사원> 테이블을 정의하는 SQL문, 요구사항을 만족하는 SQL문을 작성하라.
- '근무지번호'는 <근무지> 테이블의 '근무지번호'를 참조하는 외래키이다.
- <근무지> 테이블에서 '근무지번호'가 사가제되면 <사원> 테이블의 '근무지번호'도 삭제된다.
CREATE TABLE 사원 (
사원번호 NUMBER(4) PRIMARY KEY,
사원명 VARCHAR(10),
근무지번호 NUMBER(2) FOREIGN KEY REFERENCES 근무지
ON DELETE CASCADE));
CREATE VIEW
- 뷰(View)를 정의하는 명령문
- 표기 형식
CREATE VIEW 뷰명 [(속성명[, 속성명 ...])]
AS SELECT 문
ex) 요구사항을 만족하는 뷰 <CC> 를 정의하는 SQL 문을 작성하라.
- <Course>와 <Instruction> 릴레이션을 이용한다.
- <Course>의 'Instructor' 속성 값과 <instructor>의 id 속성이 같은 자료에 대한 view 를 정의한다.
- <CC> 뷰는 'ccid', 'ccname', 'instname' 속성을 가진다.
- <CC> 뷰는 <Course> 테이블의 'id', 'name' , <Instructor> 테이블의 'name' 속성을 사용한다.
CREATE VIEW CC(ccid, ccname, instname)
AS SELECT Course.id, Course.name, Instructor.name
FROM Course, Instructor
WHERE Course.instructor = instructor.id
CREATE INDEX
- 인덱스를 정의하는 명령문
- 표기 형식
CREATE [UNIQUE] INDEX 인덱스명
ON 테이블명(속성명 [ASC | DESC][, 속성명[ASC|DESC])
[CLUSTER];
ex) student 테이블에서 name 속성으로 idx_name 이라는 인덱스를 생성하는 SQL 문을 작성해라
CREATE INDEX idx_name
ON student(name)
ALTER TABLE
- 테이블에 대한 정의를 변경하는 명령문
- 표기 형식
ALTER TABLE 테이블명 ADD 속성명 데이터_타입 [DEFAULT '기본값'];
ALTER TABLE 테이블명 ALTER 속성명 [SET DEFAULT '기본값'];
ALTER TABLE 테이블명 DROP COLUMN 속성명 [CASCADE];- ADD : 새로운 속성(열)을 추가할 때 사용
- ALTER : 특정 속성의 Default 값을 변경할 때 사용
- DROP COLUMN : 특정 속성을 삭제할 때 사용
ex) <학생> 테이블에 20자의 가변 길이를 가진 '주소' 속성을 추가하는 SQL 문을 작성해라
ALTER TABLE 학생 ADD 주소 VARCHAR(20)
DROP
- 스키마, 도메인, 기본 테이블, 뷰 테이블, 인덱스, 제약 조건등을 제거하는 명령문
- 표기 형식
DROP SCHEMA 스키마명 [CASCADE|RESTRICT];
DROP DOMAIN 도메인명 [CASCADE|RESTRICT];
DROP TABLE 테이블명 [CASCADE|RESTRICT];
DROP VIEW 뷰명 [CASCADE|RESTRICT];
DROP INDEX 인덱스명 [CASCADE|RESTRICT];
DROP CONSTRAINT 제약조건명;- CASCADE : 제거할 요소를 참조하는 다른 모든 개체를 함께 제거
- RESTRICT : 다른 개체가 제거할 요소를 참조중일 때는 제거를 취소함
ex) <학생> 테이블을 제거하되, <학생> 테이블을 참조하는 모든 데이터를 함께 제거하는 SQL 문을 작성해라
DROP TABLE 학생 CASCADE;
DCL
- 데이터의 보안, 무결성, 회복, 병행 제어 등을 정의하는데 사용하는 언어
- 종류
| COMMIT | 명령에 의해 수행된 결과를 실제 물리적 디스크로 저장하고 작업 완료를 관리자에게 알려줌 |
| ROLLBACK | DB 조작 작업이 비정상적으로 종료되었을 때 원래 상태로 복구 |
| GRANT | DB 사용자에게 사용 권한을 부여함 |
| REVOKE | DB 사용자의 사용 권한을 취소함 |
GRANT/REVOKE
- GRANT : 권한 부여를 위한 명령어
- REVOKE : 권한 취소를 위한 명령어
- 표기 형식
// GRANT
GRANT 권한 리스트 ON 개체 TO 사용자 [WITH GRANT OPTION]
// REVOKE
REVOKE [GRANT OPTION FOR] 권한_리스트 ON 개체 FROM 사용자[CASCADE]
ex) 사용자 PARK에게 테이블 [STUDENT]의 데이터를 갱신할 수 있는 시스템 권한을 부여하는 SQL 문을 작성해라
GRANT UPDATE ON STUDENT TO PARK;
ex) 사용자 PARK에게 테이블 [STUDENT] 의 데이터를 갱신할 수 있는 시스템 권한을 취소하는 SQL 문을 작성해라
REVOKE UPDATE ON STUDENT FROM PARK;
ROLLBACK
- 변경되었으나 아직 COMMIT 되지 않은 모든 내용들을 취소하고 데이터베이스를 이전 상태로 되돌리는 명령어
SAVEPOINT
- 트랜잭션 내에 ROLLBACK 할 위치인 저장점을 지정하는 명령어
DML
- 저장된 데이터를 실질적으로 관리하는데 사용되는 언어
- DML의 유형 (SELECT , INSERT , DELETE , UPDATE)
삽입문 (INSERT INTO ~)
- 표기 형식
INSERT INTO 테이블명([속성명1, 속성명2 ...]) VALUES (데이터1,데이터2 ...);
ex) <사원> 테이블에 이름, 부서, 생일, 주소, 기본급 속성이 있을 때 <사원> 테이블에 있는 편집부의 모든 튜플을 편집부원(이름, 생일, 주소, 기본급) 테이블에 삽입하는 SQL 문을 작성해라
INSERT INTO 편집부원(이름,생일,주소,기본급)
SELECT 이름, 생일, 주소, 기본급
FROM 사원
WHERE 부서 = '편집';
삭제문 (DELETE FROM ~)
- 표기 형식
DELETE FROM 테이블명 [WHERE 조건]
ex) <사원> 테이블에서 부서가 "인터넷"인 모든 튜플을 삭제하는 SQL을 작성해라
DELETE FROM 사원
WHERE 부서 = '인터넷';
갱신문 (UPDATE ~ SET ~)
- 표기 형식
UPDATE 테이블명
SET 속성명 = 데이터 ...
[WHERE 조건];
ex) <사원> 테이블에서 "황진이"의 "부서"를 "기획부"로 변경하고 "기본급"을 5만원 인상시키는 SQL문을 작성해라.
UPDATE 사원
SET 부서 = '기획부', 기본급 = 기본급 + 5
WHERE 이름 = '황진이';
SELECT
- 표기 형식
SELECT [PREDICATE][테이블명] 속성명[AS 별칭] ...
FROM 테이블명[, 테이블명 ...]
[WHERE 조건]
[GROUP BY 속성명, 속성명 , ...]
[HAVING 조건]
[ORDER BY 속성명 [ASC|DESC]- PREDICATE : 검색할 튜플 수를 제한하는 명령어를 기술 (= DISTINCT : 중복된 튜플은 첫 번째 한개만 표시)
ex) <사원> 테이블에서 '주소'만 검색하되 같은 '주소'는 한 번만 출력하는 SQL문을 작성해라.
SELECT DISTINCT 주소 FROM 사원;
조건 지정 검색
- 비교 연산자 : = , < > (같지 않다) , > , < , >= , <=
- 논리 연산자 : NOT , AND, OR
- LIKE 연산자 : % (모든 문자 대표) , _ (문자 하나 대표) , #(숫자 하나를 대표)
ex) <사원> 테이블에서 성이 '김'인 사람과 '생일'이 '01/01/69' 에서 '12/31/73' 사이인 튜플을 검색하는 SQL문을 작성해라
SELECT *
FROM 사원
WHERE (이름 LIKE '김%') AND (생일 BETWEEN #01/01/69# AND #12/31/73#)
정렬 검색
- ORDER BY 절에 특정 속성을 지정하여 지정된 속성으로 자료를 정렬해 검색
ex) <사원> 테이블에서 '부서'를 기준으로 오름차순 , '이름'을 기준으로 내림차순 정렬 시켜 검색하는 SQL 문을 작성해라
SELECT *
FROM 사원
ORDER BY 부서 ASC, 이름 DESC;
하위 질의
- 조건절에 주어진 질의를 먼저 수행하여 그 검색 결과를 조건절의 피연산자로 사용
ex) '취미'가 '나이트댄스'인 사원의 '이름'과 '주소'를 검색하는 SQL 문을 작성해라
SELECT 이름, 주소
FROM 사원
WHERE 이름 = (SELECT 이름 FROM 여가활동 WHERE 취미 = '나이트댄스');
그룹 함수
- COUNT(속성명) : 그룹별 튜플 수 구하는 함수
- SUM(속성명) : 그룹별 합계 구하는 함수
- AVG(속성명) : 그룹별 평균을 구하는 함수
- MAX(속성명) : 그룹별 최대값을 구하는 함수
- MIN(속성명) : 그룹별 최소값을 구하는 함수
- STDDEV(속성명) : 그룹별 표준편차 구하는 함수
- VARIANCE(속성명) : 그룹별 분산을 구하는 함수
그룹 지정 검색
- GROUP BY 절에 지정한 속성을 기준으로 자료를 그룹화하여 검색한다.
ex) <상여금> 테이블에서 '상여금'이 100이상인 사원이 2명이상인 '부서'의 튜플수를 구하는 SQL 문을 작성해라.
SELECT 부서, COUNT(*) AS 사원수
FROM 상여금
WHERE 상여금 >= 100
GROUP BY 부서
HAVING COUNT(*) >= 2;
집합 연산자를 이용한 통합 질의
- UNION : 두 SELECT 문의 조회 결과를 통합하여 모두 출력 (중복은 한 번만 출력)
- UNION ALL : UNION 과 동일하지만 중복 행도 모두 출력
- INTERSECT : 두 SELECT 문 조회 결과 중 공통된 행만 출력 (교집합)
- EXCEPT : 첫 번째 SELECT문의 조회 결과에서 두 번째 SELECT문의 조회 결과를 제외한 행 출력 (차집합)
JOIN
- 연관된 튜플들을 결합하여 , 하나의 새로운 릴레이션을 반환
- INNER JOIN, OUTER JOIN으로 구분
EQUI JOIN
- 대상 테이블에서 공통 속성을 기준으로 = (equal) 비교에 의해 같은 값을 가지는 행을 연결해 결과를 생성하는 INNER JOIN 방법
WHERE절을 이용한 EQUI JOIN의 표기
SELECT [테이블명1] 속성명 , [테이블명2] 속성명, ...
FROM 테이블명1, 테이블명2 ...
WHERE 테이블명1.속성명 = 테이블명2.속성명
NATURAL JOIN절을 이용한 EUQI JOIN의 표기 형식
SELECT [테이블명1] 속성명 , [테이블명2] 속성명, ...
FROM 테이블명1 NATURAL JOIN 테이블명2
JOIN ~ USING 절을 이용한 EQUI JOIN의 표기 형식
SELECT [테이블명1]속성명, [테이블명2]속성명 ...
FROM 테이블명1 JOIN 테이블명2 USING (속성명);
OUTER JOIN
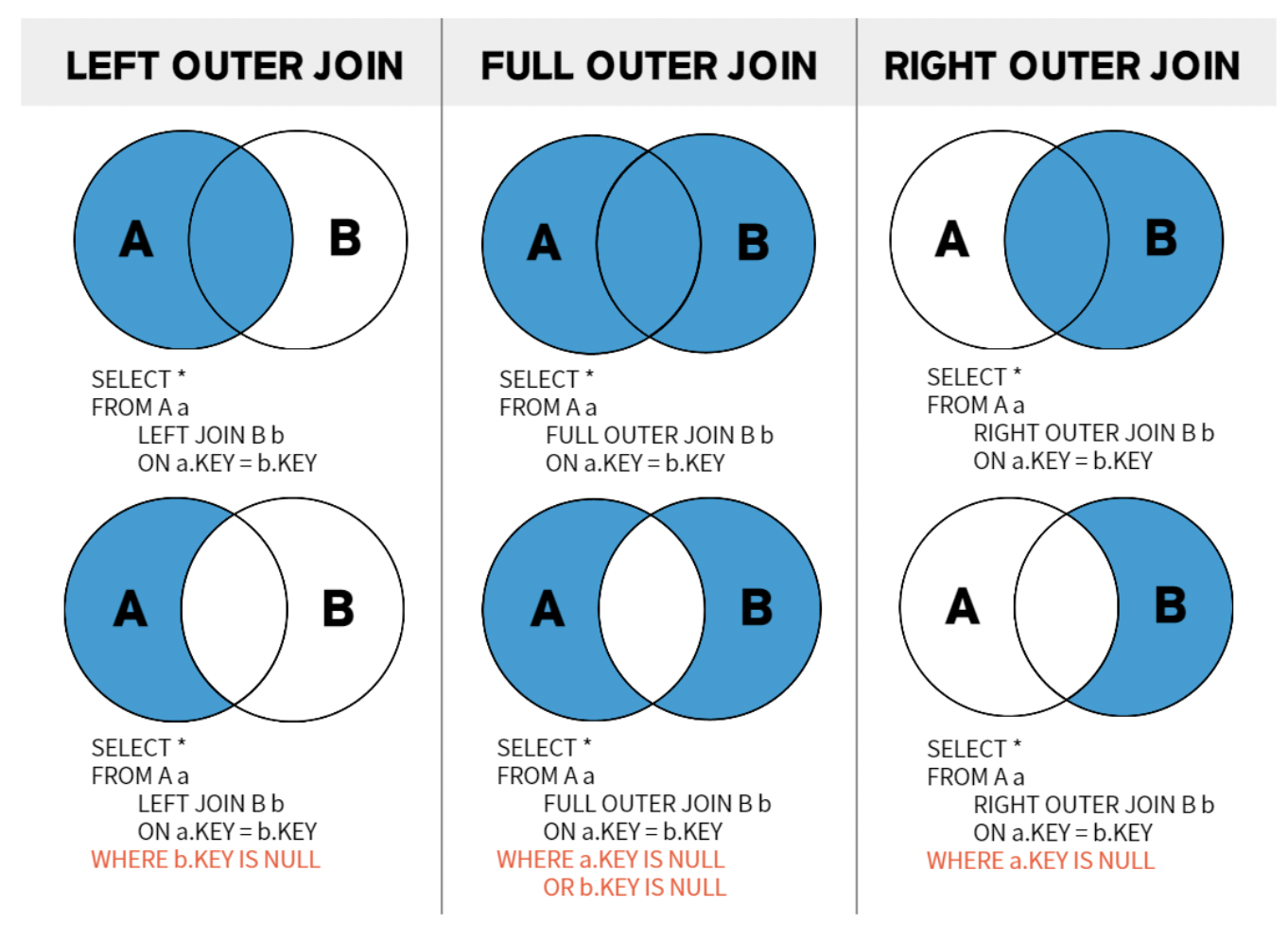
- INNER JOIN의 결과를 구한 후 우측 항 릴레이션의 어떤 튜플과도 맞지 않는 좌측 항의 릴레이션에 있는 튜플들에 NULL 값을 붙여 INNER JOIN의 결과에 추가함
- 표기 형식
SELECT [테이블명1]속성명, [테이블명2]속성명, ...
FROM 테이블명1 LEFT OUTER JOIN 테이블명2
ON 테이블명1.속성명 = 테이블명2.속성명;
트리거
- 이벤트가 발생할 때 관련 작업이 자동으로 수행되게 하는 절차형 SQL
커서
- 쿼리문의 처리 결과가 저장되어 있는 메모리 공간을 가리키는 포인터(Pointer)
- 묵시적 커서 : 자동으로 생성되는 커서 (DBMS에 의해)
- 명시적 커서 : 사용자가 직접 정의해서 사용하는 커서
- 속성의 종류
| SQL%FOUND | 쿼리 수행 결과로 패치된 튜플 수가 1개 이상이면 TRUE |
| SQL%NOTFOUND | 쿼리 수행 결과로 패치된 튜플 수가 0개이면 TRUE |
| SQL%ROWCOUNT | 쿼리 수행 결과로 패치 된 튜플수를 반환 |
| SQL%ISOPEN | 커서가 열린 상태면 TRUE , 묵시적 커서는 자동 생성후 자동 닫히므로 항상 FALSE |
DBMS 접속 기술의 종류
- DBMS에 접근하기 위해 사용하는 API 또는 API의 사용을 편리하게 도와주는 프레임워크
- JDBC : Java언어로 DB 접속 시 사용하는 표준 API
- ODBC : 언어 관계 없이 DB 접근을 위한 표준 개방형 API ( MS사에서 개발 )
- MyBatis : JDBC 코드를 단순화하여 사용할 수 있는 SQL Mapping 기반 오픈 소스 접속 프레임워크 , SQL문장을 분리해 XML 파일을 만들고 Mapping을 통해 SQL을 실행한다.
동적 SQL
- SQL 구문을 동적으로 변경하여 처리할 수 있는 SQL 처리 방식
ORM
- 객체와 관계형 데이터베이스의 데이터를 연결하는 기술
- 종류
| 기반 언어 | ORM 프레임워크 |
| Java | JPA, Hibernate, EcplishLink, DataNucleus, Ebean 등 |
| C++ | ODB, QxOrm |
| Python | Django, SQLAIchemy, Storm |
| .NET | NHibernate, DatabaseObjects, Dapper |
| PHP | Doctrine, Propel, RedBean |
쿼리 성능 관련 용어
- APM : 성능 관리를 위해 접속자, 자원 현황, 트랜잭션 수행 내역 등 다양한 모니터링 기능을 제공하는 도구
- 옵티마이저 (Optimizer) : 작성된 SQL이 가장 효율적으로 수행되도록 최적의 경로를 찾아주는 모듈
- RBO : DBA가 사전에 정의해둔 규칙에 의거하여 경로를 찾는 규칙 기반 옵티마이저
- CBO : 입출력 속도, CPU 사용량, 블록 개수 등을 종합하여 산출되는 '비용'으로 최적의 경로 찾는 비용 기반 옵티마이저
- 실행 계획 : DBMS의 옵티마이저가 수립한 SQL 코드의 실행 절차와 방법
- 힌트 : SQL문에 추가되어 테이블 접근 순서를 변경하거나, 인덱스 사용을 강제하는 등 실행 계획에 영향을 줄 수 있는 문장
- IOT : 인덱스 안에 테이블 데이터를 직접 삽입하여 저장함으로써 주소를 얻는 과정을 생략하여 빠른 조회가 가능하도록 구성한 테이블